
研究领域:信息检索(information retrieval)
任务定义:文档检索 是从 大型文档集合 中 查找与特定查询相关的文档的任务
下游任务:开放域问答(open domain question answering)、事实核查( fact checking)……
传统做法(基于词频):利用词汇相似性来匹配查询和文档,属于稀疏方法(sparse methods)
代表方法:TF-IDF、BM25
问题所在:存在 “词汇鸿沟” 问题,泛化能力较差(suffer from the lexical gap and do not generalize well)
神经网络:能够学习词汇相似性之外的特征
缺点:
- 数据量大,手工标注不现实
- “零样本”场景,效果不如传统做法
- 除英语外,其他语言通常缺乏大规模标注数据集
过去尝试:
- 通过使用近似检索(approximates retrieva)的辅助任务,可以实现无监督密集检索器的训练。给定一个文档,可以生成一个合成查询,然后训练网络在给定查询的情况下从多个文档中检索原始文档
- 逆完型填空任务(inverse Cloze task (ICT)) :用于预训练检索器,该任务使用给定句子作为查询,并预测其周围的上下文。作为零样本检索器时性能仍落后于 BM25
提出背景:使用神经网络的密集检索器(dense retrievalers),在没有训练数据的新应用中迁移能力较差
文章做法:探索对比学习作为训练无监督密集检索器的方法的局限性,并表明它在各种检索场景中具有强大的性能
模型结构:使用双编码器架构,其中文档和查询独立编码,相关度得分由两者表示向量的点积计算得出。
其中q 为查询,d为文档,f_\theta 为 Transformer 网络
对比学习的核心假设是:每个文档在某种意义上是唯一的,这种唯一性信号是无监督场景下唯一可用的信息。损失函数如下:
k_+ 正样本文档,\{k_i\}^K_{i=1} 为负样本集合。(注意这里,正样本为单个,而负样本为集合。目前的猜测是:如果正样本也是集合的话,其中一个很大,结果就会大,不便于判断是否真的学会)\tau 为温度系数
文中提到了两种构建正样本对的方法:
- ICT,从文档中随机采样一个片段作为查询,剩余文档作为键(有的做法,会10%保留裁剪的内容)
- 独立裁剪:从文档中独立采样两个片段形成正样本对。(允许片段重叠)
- 其他数据增强:随机词删除、替换或掩码等增强方式,作为随机裁剪的补充
构建大规模负样本集合
- 批次内负样本(In-batch Negatives):将同一批次中的其他样本作为负样本。此方法的梯度需反向传播至查询和键的表示,但需要极大的批次规模才能有效
- 跨批次负样本(Negatives across Batches):将历史批次的表示存入队列,作为当前批次的负样本。允许较小批次规模,但会引入不对称性。(这里提到了MoCo技术)
最终做法:带随机裁剪的 MoCo 方法
数据集和评价指标
数据集
- 维基百科数据和 CCNet 数据混合样本:用于训练
- NaturalQuestions 和 TriviaQA:用于评估
- BEIR 基准:评估。BEIR 的大多数数据集不含训练集,其核心目标是评估零样本检索性能
- MS MARCO:用于监督微调的
- Mr. TyDi:评估mContriever
- MKQA:评估mContriever
评价指标:
- 报告 top-k 检索准确率,即至少有一个 top-k 段落包含答案的问题数量占比:对于QA数据集
- nDCG@10 :关注前 10 名检索文档的排序质量,适用于评估搜索引擎返回给用户的排名
- Recall@100 :适用于评估机器学习系统(如问答系统)中的检索器性能,这类系统可处理数百篇文档并忽略其排序
辅助材料
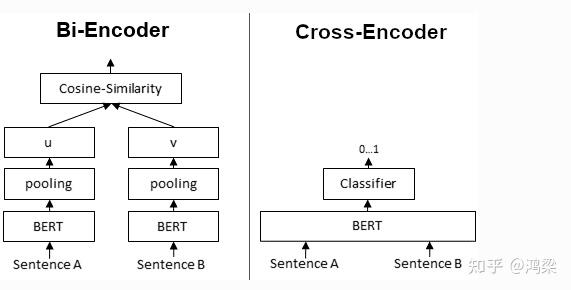
Bi-Encoder 和 Cross-Encoder 分别是什么?
Bi-Encoder:给定句子生成句子的embedding。我们将句子 A 和 B 独立地传递给 BERT,从而产生句子嵌入 u 和 v,然后可以使用余弦相似度比较。
Cross-Encoder:同时将两个句子传递给 Transformer 网络。它产生一个介于 0 和 1 之间的输出值,表示输入句对的相似性。不产生句子的 embedding。 并且,无法将单个句子传递给Cross-Encoder。
评价指标的释义:
对于检索结果,通常排序靠前的结果往往更加重要,因此这些评价指标都会针对top-k结果进行计算(记作@k)
可能需要了解的一些内容
- TF-IDF
- BM25
- DPR
- 对比学习
- hard negative 是什么
- MoCo
- 通过交叉编码器对检索文档进行重排序(This strong recall@100 performance can be further exploited by using a cross-encoder2 to re-rank the retrieved documents)?这是什么
- negative mining and do not use distillation